Attention 机制的就地 KV 缓存¶
基于 Attention 的模型中的 KV 缓存是指在自回归生成过程中存储先前计算的 Key 和 Value 张量的机制。在仅解码器 Transformer 中,每个新 token 都必须使用 Attention 机制关注所有先前的 token。通常,这需要在每个时间步为每个先前的 token 重新计算 Key 和 Value 投影,这效率低下。相反,KV 缓存会在这些投影首次计算后存储它们,从而允许模型在不重新计算的情况下为未来的 token 重用它们。这显著加快了生成过程。
就地更新 KV 缓存意味着将新的 Key 和 Value 张量直接写入预分配的内存中,索引对应于序列中的当前位置。这有几个优点:它避免了重复的内存分配或复制,从而减少了计算开销;通过启用融合内核和减少内存带宽使用,它还可以在硬件加速器上实现更好的性能。就地更新对于在推理过程中实现高吞吐量和低延迟至关重要,特别是对于部署在实时应用中的大型语言模型。
ONNX opset-24 引入了新功能,以方便表示就地 KV 缓存更新。此图显示了一个示例用例。
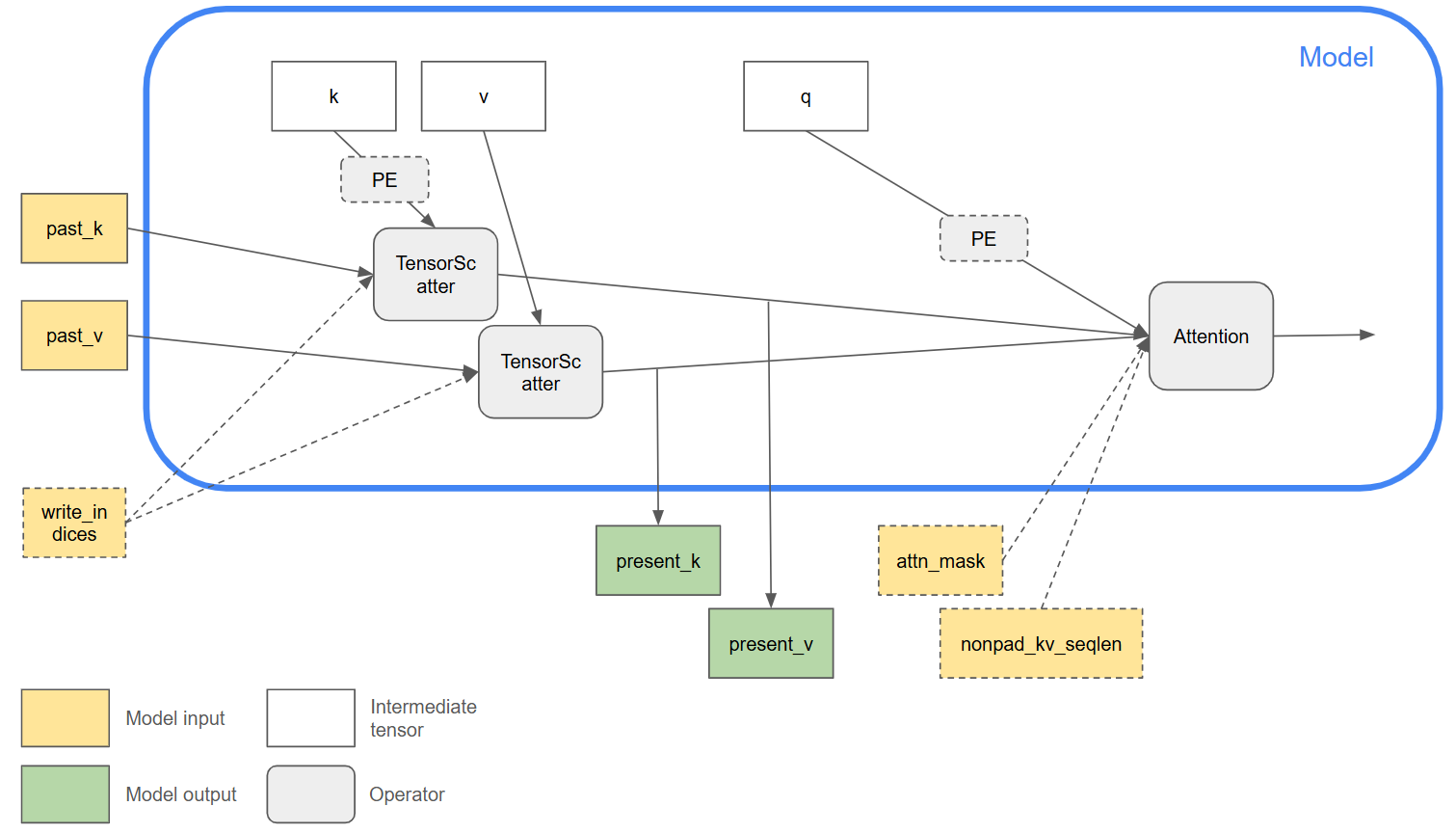
Attention操作的K和V输入包含整个 KV 缓存张量,其中序列长度维度是 max_sequence_length,因此这些输入的大小在自回归迭代之间不会增长。因此,可以使用可选的nonpad_kv_seqlen输入来指示每个样本中有效(非填充)token 的数量,以跳过不必要的计算。KV 缓存更新的逻辑已从
Attention操作中分离出来。TensorScatter操作可用于更新缓存张量,其中当前迭代的传入 Key 和 Value token 根据write_indices分散到缓存张量中。作为一种优化,后端可以自由地将过去和当前的 Key/Value 张量别名,以避免复制缓存张量并实现就地更新。为了使此优化有效,后端需要确保
TensorScatter的输入不会被其他操作后续重用。只有这样,才能安全地将分配给操作的past_k/v输入的内存用于present_k/v输出。相同的计算图可用于自回归模型的预填充和解码阶段。
提醒一下,ONNX 表示仍然是功能表示,其中操作是纯函数。上面描述的图布局是表达就地 KV 缓存更新的有用常见模式,输入/输出别名完全取决于后端实现。