ONNX 概念¶
ONNX 可以被比作一种专门用于数学函数编程语言。它定义了机器学习模型需要使用这种语言实现其推理功能的所有必要操作。线性回归可以表示为以下形式:
def onnx_linear_regressor(X):
"ONNX code for a linear regression"
return onnx.Add(onnx.MatMul(X, coefficients), bias)
这个例子与开发人员在 Python 中编写的表达式非常相似。它也可以表示为一个图,逐步展示如何转换特征以获得预测。这就是为什么使用 ONNX 实现的机器学习模型通常被称为 ONNX 图。
ONNX 旨在提供一种通用的语言,任何机器学习框架都可以用来描述其模型。第一个场景是使其更容易在生产环境中部署机器学习模型。ONNX 解释器(或 运行时)可以在部署环境中专门为此任务实现和优化。通过 ONNX,可以构建一个独特的流程,在生产环境中部署模型,并且独立于用于构建模型的学习框架。onnx 实现了一个 Python 运行时,可用于评估 ONNX 模型和评估 ONNX 操作。这旨在阐明 ONNX 的语义,并帮助理解和调试 ONNX 工具和转换器。它不打算用于生产,性能也不是目标(参见onnx.reference)。
输入、输出、节点、初始化器、属性¶
构建 ONNX 图意味着使用 ONNX 语言或更确切地说是ONNX 算子来实现一个函数。线性回归将这样编写。以下行不遵循 Python 语法。它只是一种伪代码,用于说明模型。
Input: float[M,K] x, float[K,N] a, float[N] c
Output: float[M, N] y
r = onnx.MatMul(x, a)
y = onnx.Add(r, c)
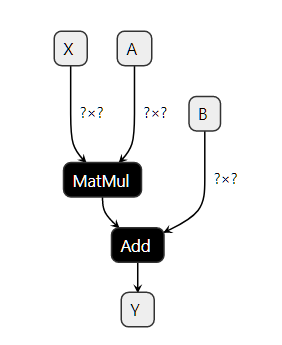
此代码实现函数 f(x, a, c) -> y = x @ a + c。其中 x、a、c 是输入,y 是输出。r 是中间结果。MatMul 和 Add 是节点。它们也有输入和输出。节点也有类型,是ONNX 算子中的一个。此图是使用一个简单示例:线性回归部分中的示例构建的。
该图也可以有一个初始化器。当一个输入永不改变时,例如线性回归的系数,最有效的方法是将其转换为存储在图中的常量。
Input: float[M,K] x
Initializer: float[K,N] a, float[N] c
Output: float[M, N] xac
xa = onnx.MatMul(x, a)
xac = onnx.Add(xa, c)
在视觉上,该图将如下图所示。右侧描述了算子 Add,其中第二个输入被定义为初始化器。该图是通过此代码获得的初始化器,默认值。
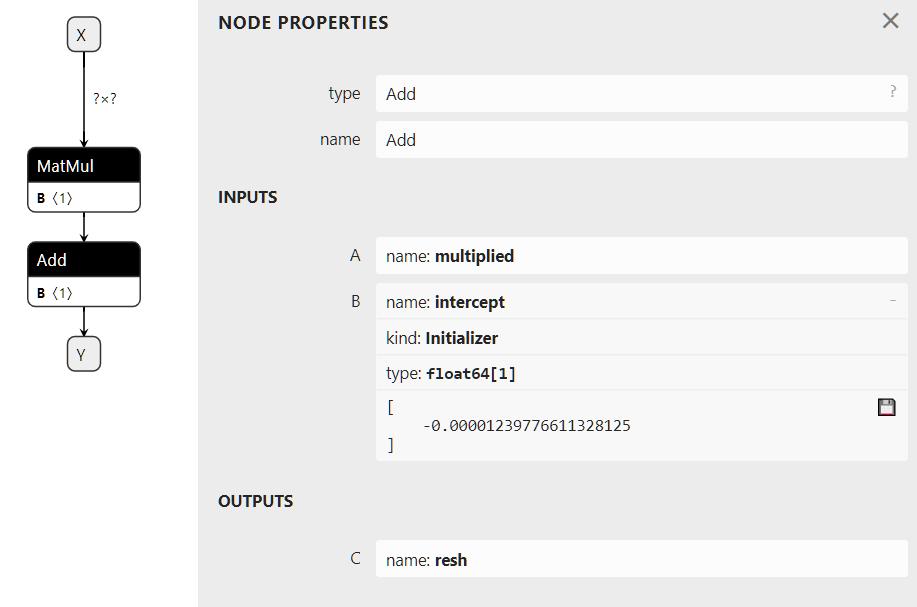
属性是算子的固定参数。算子Gemm有四个属性:alpha、beta、transA、transB。除非运行时通过其 API 允许,否则一旦加载 ONNX 图,这些值就无法更改,并且在所有预测中都保持冻结状态。
使用 protobuf 进行序列化¶
将机器学习模型部署到生产环境通常需要复制用于训练模型的整个生态系统,大多数时候使用 docker。一旦模型转换为 ONNX,生产环境只需要一个运行时来执行由 ONNX 算子定义的图。这个运行时可以用适用于生产应用程序的任何语言开发,例如 C、Java、Python、JavaScript、C#、Webassembly、ARM 等。
但要实现这一点,ONNX 图需要保存。ONNX 使用 protobuf 将图序列化为一个块(参见解析和序列化)。它的目标是尽可能优化模型大小。
元数据¶
机器学习模型不断更新。记录模型版本、模型作者以及训练方式非常重要。ONNX 提供了在模型本身中存储额外数据的可能性。
- doc_string:此模型的人类可读文档。
允许使用 Markdown。
- domain:反向 DNS 名称,用于指示模型命名空间或域,
例如,“org.onnx”
- metadata_props:命名元数据,作为字典
map<string,string>, (values, keys)应不重复。
- metadata_props:命名元数据,作为字典
- model_author:逗号分隔的名称列表,
模型作者的个人姓名和/或其组织。
- model_license:许可证的知名名称或 URL
模型在此许可证下可用。
model_version:模型本身的版本,以整数编码。
producer_name:用于生成模型的工具名称。
producer_version:生成工具的版本。
- training_info:包含的可选扩展
训练信息(参见TrainingInfoProto)
可用算子和域的列表¶
主要列表在此处描述:ONNX 算子。它合并了标准矩阵算子(Add、Sub、MatMul、Transpose、Greater、IsNaN、Shape、Reshape……)、归约(ReduceSum、ReduceMin、……)图像变换(Conv、MaxPool、……)、深度神经网络层(RNN、DropOut、……)、激活函数(Relu、Softmax、……)。它涵盖了实现标准和深度机器学习推理功能所需的大部分操作。ONNX 没有实现所有现有的机器学习算子,算子列表将是无限的。
主要的算子列表以域 ai.onnx 标识。域可以定义为一组算子。此列表中的少数算子专用于文本,但它们很难满足需求。主要列表也缺少在标准机器学习中非常流行的基于树的模型。这些属于另一个域 ai.onnx.ml,它包括基于树的模型(TreeEnsemble Regressor, ...)、预处理(OneHotEncoder, LabelEncoder, ...)、SVM 模型(SVMRegressor, ...)、插值器(Imputer)。
ONNX 只定义了这两个域。但是 onnx 库支持任何自定义域和算子(参见可扩展性)。
支持的类型¶
ONNX 规范针对张量数值计算进行了优化。张量是多维数组。它由以下部分定义:
类型:元素类型,张量中所有元素都相同
形状:包含所有维度的数组,此数组可以为空,维度可以为 null
连续数组:它表示所有值
此定义不包括“步幅”或基于现有张量定义张量视图的可能性。ONNX 张量是密集的完整数组,没有步幅。
元素类型¶
ONNX 最初是为了帮助部署深度学习模型而开发的。因此,其规范最初是为浮点数(32 位)设计的。当前版本支持所有常见类型。字典 l-onnx-types-mapping 给出了 ONNX 和 numpy 之间的对应关系。
import re
from onnx import TensorProto
reg = re.compile('^[0-9A-Z_]+$')
values = {}
for att in sorted(dir(TensorProto)):
if att in {'DESCRIPTOR'}:
continue
if reg.match(att):
values[getattr(TensorProto, att)] = att
for i, att in sorted(values.items()):
si = str(i)
if len(si) == 1:
si = " " + si
print("%s: onnx.TensorProto.%s" % (si, att))
1: onnx.TensorProto.FLOAT
2: onnx.TensorProto.UINT8
3: onnx.TensorProto.INT8
4: onnx.TensorProto.UINT16
5: onnx.TensorProto.INT16
6: onnx.TensorProto.INT32
7: onnx.TensorProto.INT64
8: onnx.TensorProto.STRING
9: onnx.TensorProto.BOOL
10: onnx.TensorProto.FLOAT16
11: onnx.TensorProto.DOUBLE
12: onnx.TensorProto.UINT32
13: onnx.TensorProto.UINT64
14: onnx.TensorProto.COMPLEX64
15: onnx.TensorProto.COMPLEX128
16: onnx.TensorProto.BFLOAT16
17: onnx.TensorProto.FLOAT8E4M3FN
18: onnx.TensorProto.FLOAT8E4M3FNUZ
19: onnx.TensorProto.FLOAT8E5M2
20: onnx.TensorProto.FLOAT8E5M2FNUZ
21: onnx.TensorProto.UINT4
22: onnx.TensorProto.INT4
23: onnx.TensorProto.FLOAT4E2M1
24: onnx.TensorProto.FLOAT8E8M0
ONNX 具有强类型,其定义不支持隐式转换。ONNX 不允许添加不同类型的两个张量或矩阵,即使其他语言允许。因此,必须在图中插入显式转换。
稀疏张量¶
稀疏张量对于表示具有许多零系数的数组非常有用。ONNX 支持 2D 稀疏张量。SparseTensorProto 类定义了属性 dims、indices (int64) 和 values。
其他类型¶
除了张量和稀疏张量之外,ONNX 还通过类型SequenceProto、MapProto支持张量序列、张量映射、张量映射序列。它们很少使用。
什么是算子集版本?¶
算子集版本与 onnx 包的版本对应。每次次版本号增加时,它都会递增。每个版本都会带来更新或新的算子。
import onnx
print(onnx.__version__, " opset=", onnx.defs.onnx_opset_version())
1.20.0 opset= 25
算子集版本也附加到每个 ONNX 图。它定义了图中所有算子的版本。算子 Add 在版本 6、7、13 和 14 中更新。如果图的算子集版本是 15,则表示算子 Add 遵循规范版本 14。如果图的算子集版本是 12,则算子 Add 遵循规范版本 7。图中一个算子遵循其低于(或等于)全局图算子集的最新定义。
一个图可能包含来自多个域的算子,例如 ai.onnx 和 ai.onnx.ml。在这种情况下,图必须为每个域定义一个全局算子集版本。该规则适用于同一域中的所有算子。
子图、条件和循环¶
ONNX 实现了条件和循环。它们都将另一个 ONNX 图作为属性。这些结构通常缓慢而复杂。如果可能,最好避免使用它们。
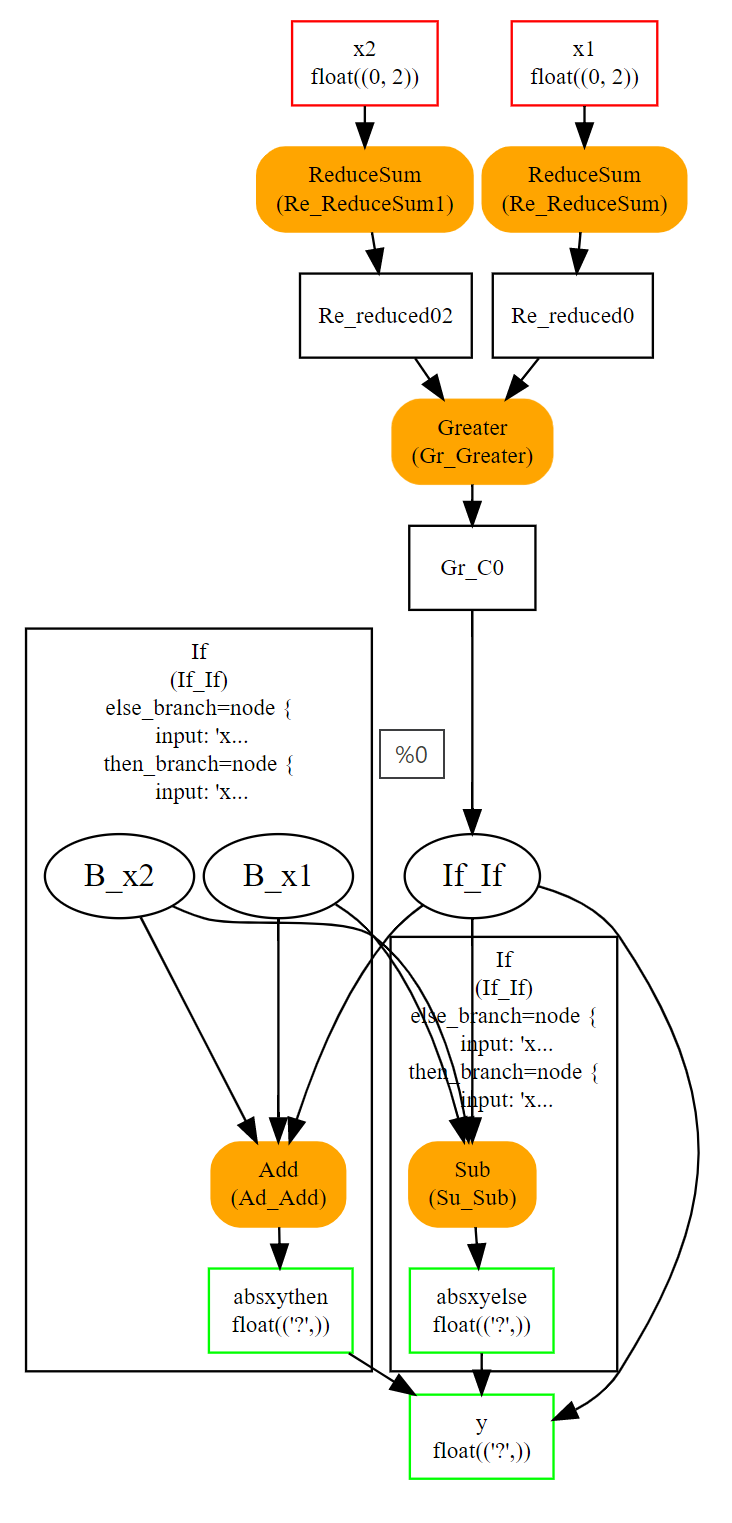
If¶
算子If根据条件评估执行两个图中的一个。
If(condition) then
execute this ONNX graph (`then_branch`)
else
execute this ONNX graph (`else_branch`)
这两个图可以使用图中已经计算出的任何结果,并且必须生成完全相同数量的输出。这些输出将是 If 算子的输出。
Scan¶
算子Scan实现了一个固定迭代次数的循环。它遍历输入的行(或任何其他维度),并沿同一轴连接输出。让我们看一个实现成对距离的示例:\(M(i,j) = \lVert X_i - X_j \rVert^2\)。
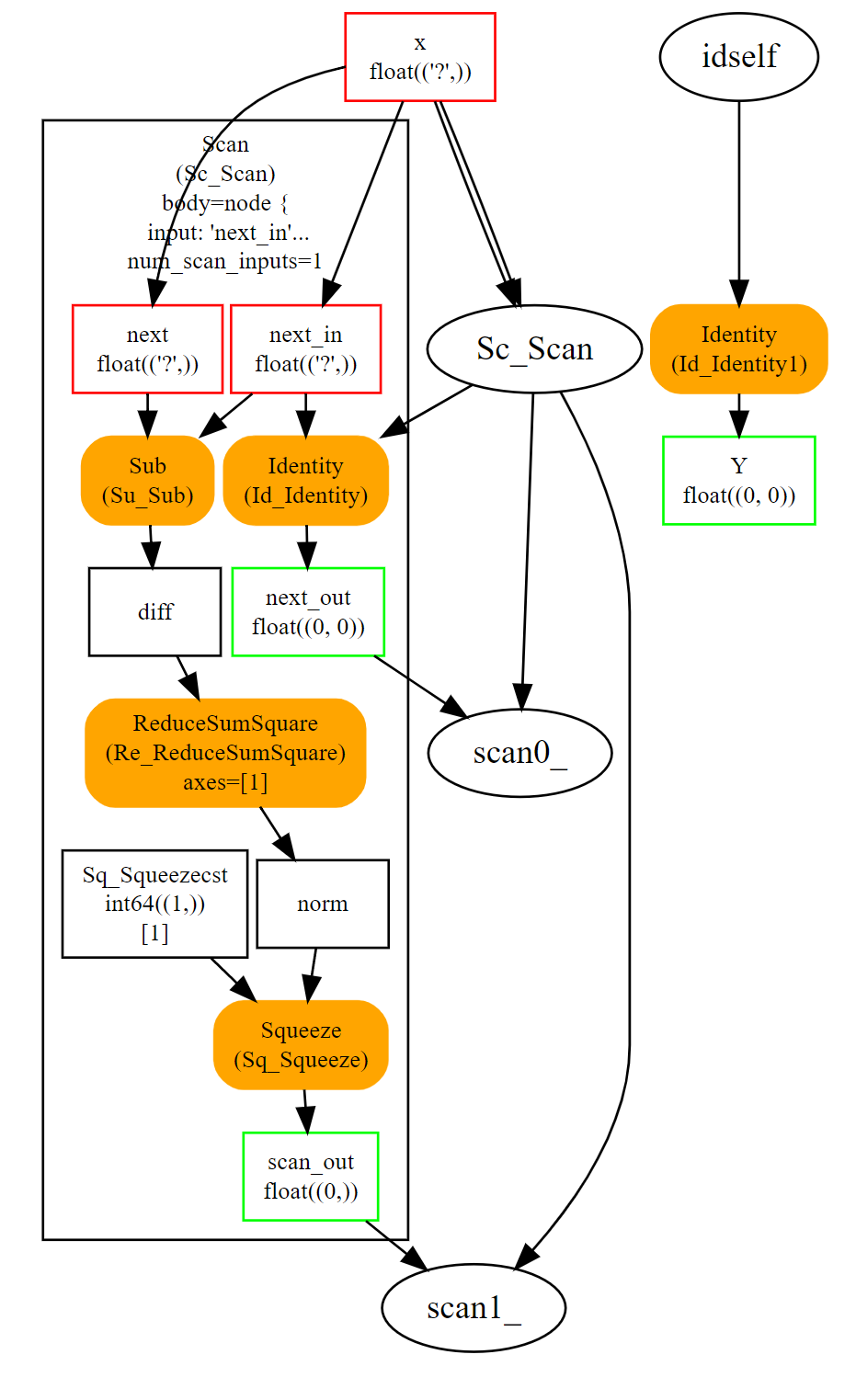
这个循环效率很高,尽管仍然比成对距离的自定义实现慢。它假设输入和输出是张量,并自动将每次迭代的输出连接成单个张量。前面的示例只有一个,但它可以有多个。
Loop¶
算子Loop实现了 for 循环和 while 循环。它可以执行固定次数的迭代,并且/或者在条件不再满足时结束。输出以两种不同的方式处理。第一种与循环Scan相似,输出被连接到张量中(沿第一维)。这也意味着这些输出必须具有兼容的形状。第二种机制将张量连接成张量序列。
可扩展性¶
ONNX 将一系列算子定义为标准:ONNX 算子。但是,您完全可以在此域或新域下定义自己的算子。onnxruntime 定义了自定义算子以提高推理性能。每个节点都有类型、名称、命名输入和输出以及属性。只要一个节点在这些约束下被描述,就可以将一个节点添加到任何 ONNX 图中。
成对距离可以使用 Scan 算子实现。然而,一个名为 CDist 的专用算子被证明要快得多,足以值得为它实现一个专用运行时。
函数¶
函数是扩展 ONNX 规范的一种方式。有些模型需要相同的算子组合。这可以通过创建本身由现有 ONNX 算子定义的函数来避免。一旦定义,函数行为就像任何其他算子一样。它有输入、输出和属性。
使用函数有两个优点。第一个是代码更短,更容易阅读。第二个是任何 onnxruntime 都可以利用这些信息来更快地运行预测。运行时可以为函数提供特定的实现,而不依赖于现有算子的实现。
形状(和类型)推断¶
了解结果的形状对于执行 ONNX 图不是必需的,但此信息可用于使其更快。如果您有以下图:
Add(x, y) -> z
Abs(z) -> w
如果 x 和 y 具有相同的形状,则 z 和 w 也具有相同的形状。知道了这一点,就可以重用为 z 分配的缓冲区,在原地计算绝对值 w。形状推断有助于运行时管理内存,从而提高效率。
ONNX 包在大多数情况下可以计算每个标准算子的输出形状,已知输入形状。显然,它无法对官方列表之外的任何自定义算子执行此操作。
工具¶
netron 在可视化 ONNX 图方面非常有用。这是唯一无需编程的工具。第一个截图就是用这个工具制作的。
onnx2py.py 从 ONNX 图创建 Python 文件。此脚本可以创建相同的图。用户可以修改它来更改图。
zetane 可以加载 ONNX 模型并在模型执行时显示中间结果。