转换管道¶
skl2onnx 将任何机器学习管道转换为 ONNX 管道。每个转换器或预测器都会被转换为 ONNX 图中的一个或多个节点。任何 ONNX 后端 都可以使用此图来计算与相同输入等效的输出。
转换复杂管道¶
scikit-learn 引入了 ColumnTransformer,它对于构建复杂管道非常有用,例如以下管道:
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.decomposition import TruncatedSVD
from sklearn.compose import ColumnTransformer
numeric_features = [0, 1, 2] # ["vA", "vB", "vC"]
categorical_features = [3, 4] # ["vcat", "vcat2"]
classifier = LogisticRegression(C=0.01, class_weight=dict(zip([False, True], [0.2, 0.8])),
n_jobs=1, max_iter=10, solver='lbfgs', tol=1e-3)
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(sparse_output=True, handle_unknown='ignore')),
('tsvd', TruncatedSVD(n_components=1, algorithm='arpack', tol=1e-4))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
model = Pipeline(steps=[
('precprocessor', preprocessor),
('classifier', classifier)
])
我们可以将其表示为
一旦拟合,模型就会被转换为 ONNX。
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType, StringTensorType
initial_type = [('numfeat', FloatTensorType([None, 3])),
('strfeat', StringTensorType([None, 2]))]
model_onnx = convert_sklearn(model, initial_types=initial_type)
注意
错误 AttributeError: 'ColumnTransformer' object has no attribute 'transformers_' 表示模型尚未训练。转换器尝试访问由 fit 方法创建的属性。
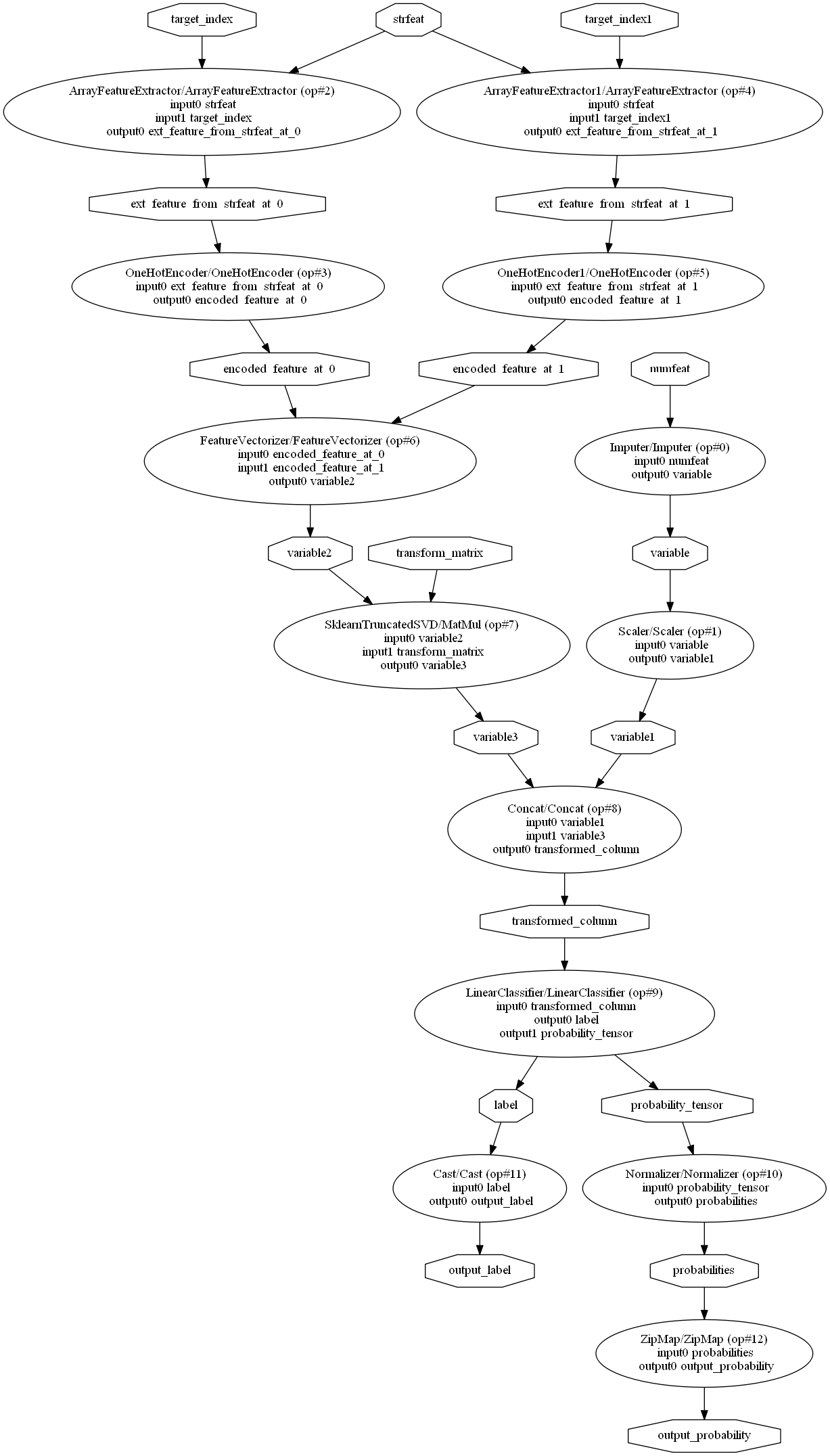
它可以表示为 DOT 图
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
pydot_graph = GetPydotGraph(model_onnx.graph, name=model_onnx.graph.name, rankdir="TP",
node_producer=GetOpNodeProducer("docstring"))
pydot_graph.write_dot("graph.dot")
import os
os.system('dot -O -Tpng graph.dot'
解析器、形状计算器、转换器¶
在转换 scikit-pipeline 时涉及三种类型的函数。它们按以下顺序调用:
parser(scope, model, inputs, custom_parser):解析器构建模型的预期输出。由于生成的图必须包含唯一的名称,因此 scope 包含所有已给出的名称。model 是要转换的模型。inputs 是模型在 ONNX 图中接收的输入。它是一个
Variable列表。custom_parsers 包含一个映射{model type: parser},该映射扩展了默认解析器列表。解析器为标准的机器学习问题定义了默认输出。形状计算器根据模型更改每个输出的形状和类型,并在定义所有输出(拓扑)后调用。此步骤定义每个节点的输出数量及其类型,并将它们设置为默认形状[None, None],其中输出节点有一行且尚未确定列数。shape_calculator(model):形状计算器更改解析器创建的输出的形状。一旦此函数返回其结果,图结构就完全定义了,并且无法更改。形状计算器不应更改类型。许多运行时是用 C++ 实现的,不支持隐式类型转换。类型更改可能会导致运行时因两个由不同转换器生成的连续节点之间的类型不匹配而失败。
converter(scope, operator, container):转换器将转换器或预测器转换为 ONNX 节点。每个节点都可以是 ONNX 运算符 或 ML 运算符 或自定义 ONNX 运算符。
由于 sklearn-onnx 可能会转换来自其他库的模型管道,因此该库必须处理来自其他包的解析器、形状计算器或转换器。这可以通过两种方式完成。第一种方法是通过映射模型类型到特定的解析器、特定的形状计算器或特定的转换器来调用 convert_sklearn 函数。可以通过使用 update_registered_converter、update_registered_parser 这两个函数之一来注册新的解析器或形状计算器或转换器,从而避免这些规范。下面是一个示例。
管道中的新转换器¶
许多库实现了 scikit-learn API,它们的模型可以包含在 scikit-learn 管道中。但是,如果 sklearn-onnx 不知道相应的转换器,则无法转换包含 XGBoost 或 LightGBM 之类的模型的管道:需要注册它们。这就是 skl2onnx.update_registered_converter() 函数的用途。以下示例展示了如何注册新转换器或更新现有转换器。会注册四个元素:
模型类
别名,通常是类名加上库名前缀
形状计算器,它计算预期输出的类型和形状
模型转换器
以下几行显示了随机森林的这四个元素
from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes
from skl2onnx.operator_converters.RandomForest import convert_sklearn_random_forest_classifier
from skl2onnx import update_registered_converter
update_registered_converter(SGDClassifier, 'SklearnLinearClassifier',
calculate_linear_classifier_output_shapes,
convert_sklearn_random_forest_classifier)
有关 LightGBM 模型的完整示例,请参阅 转换包含 LightGBM 分类器的管道。
泰坦尼克号示例¶
第一个示例来自 scikit-learn 文档的简化管道:具有混合类型的 Column Transformer。完整的故事可以在一个可运行的示例中找到:转换带有 ColumnTransformer 的管道,其中还显示了用户在尝试转换管道时可能会遇到的一些错误。
参数化转换¶
大多数转换器在转换 scikit-learn 模型时不需要特殊选项即可产生相同的结果。但是,在某些情况下,转换无法产生返回完全相同结果的模型。用户可能希望通过向转换器提供额外信息来优化转换,即使要转换的模型包含在管道中。这就是为什么实现了选项机制:带选项的转换器。
调查差异¶
错误的转换器可能会在转换后的管道中引入差异,但并非总是容易隔离差异的来源。函数 collect_intermediate_steps 可用于独立调查每个组件。以下代码片段来自单元测试 test_investigate.py,它独立转换管道及其每个组件
import numpy
from numpy.testing import assert_almost_equal
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import onnxruntime
from skl2onnx.helpers import collect_intermediate_steps, compare_objects
from skl2onnx.common.data_types import FloatTensorType
# Let's fit a model.
data = numpy.array([[0, 0], [0, 0], [2, 1], [2, 1]],
dtype=numpy.float32)
model = Pipeline([("scaler1", StandardScaler()),
("scaler2", StandardScaler())])
model.fit(data)
# Convert and collect every operator in a pipeline
# and modifies the current pipeline to keep
# intermediate inputs and outputs when method
# predict or transform is called.
operators = collect_intermediate_steps(model, "pipeline",
[("input",
FloatTensorType([None, 2]))])
# Method and transform is called.
model.transform(data)
# Loop on every operator.
for op in operators:
# The ONNX for this operator.
onnx_step = op['onnx_step']
# Use onnxruntime to compute ONNX outputs
sess = onnxruntime.InferenceSession(onnx_step.SerializeToString(),
providers=["CPUExecutionProvider"])
# Let's use the initial data as the ONNX model
# contains all nodes from the first inputs to this node.
onnx_outputs = sess.run(None, {'input': data})
onnx_output = onnx_outputs[0]
skl_outputs = op['model']._debug.outputs['transform']
# Compares the outputs between scikit-learn and onnxruntime.
assert_almost_equal(onnx_output, skl_outputs)
# A function which is able to deal with different types.
compare_objects(onnx_output, skl_outputs)
调查缺失的转换器¶
在转换管道之前,可能缺少许多转换器。当找到第一个缺失的转换器时,将引发异常 MissingShapeCalculator。可以修改前面的代码片段来查找所有缺失的转换器。
import numpy
from numpy.testing import assert_almost_equal
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import onnxruntime
from skl2onnx.common.data_types import guess_data_type
from skl2onnx.common.exceptions import MissingShapeCalculator
from skl2onnx.helpers import collect_intermediate_steps, compare_objects, enumerate_pipeline_models
from skl2onnx.helpers.investigate import _alter_model_for_debugging
from skl2onnx import convert_sklearn
class MyScaler(StandardScaler):
pass
# Let's fit a model.
data = numpy.array([[0, 0], [0, 0], [2, 1], [2, 1]],
dtype=numpy.float32)
model = Pipeline([("scaler1", StandardScaler()),
("scaler2", StandardScaler()),
("scaler3", MyScaler()),
])
model.fit(data)
# This function alters the pipeline, every time
# methods transform or predict are used, inputs and outputs
# are stored in every operator.
_alter_model_for_debugging(model, recursive=True)
# Let's use the pipeline and keep intermediate
# inputs and outputs.
model.transform(data)
# Let's get the list of all operators to convert
# and independently process them.
all_models = list(enumerate_pipeline_models(model))
# Loop on every operator.
for ind, op, last in all_models:
if ind == (0,):
# whole pipeline
continue
# The dump input data for this operator.
data_in = op._debug.inputs['transform']
# Let's infer some initial shape.
t = guess_data_type(data_in)
# Let's convert.
try:
onnx_step = convert_sklearn(op, initial_types=t)
except MissingShapeCalculator as e:
if "MyScaler" in str(e):
print(e)
continue
raise
# If it does not fail, let's compare the ONNX outputs with
# the original operator.
sess = onnxruntime.InferenceSession(onnx_step.SerializeToString(),
providers=["CPUExecutionProvider"])
onnx_outputs = sess.run(None, {'input': data_in})
onnx_output = onnx_outputs[0]
skl_outputs = op._debug.outputs['transform']
assert_almost_equal(onnx_output, skl_outputs)
compare_objects(onnx_output, skl_outputs)