注意
跳转到结尾 下载完整的示例代码。
切换到浮点数时出现的问题¶
大多数 scikit-learn 模型使用双精度(double)而非单精度(float)进行计算。深度学习中的大多数模型使用浮点数,因为这是 GPU 最常见的情况。ONNX 最初是为了方便部署深度学习模型而创建的,这解释了为什么许多转换器会假设转换后的模型应使用浮点数。这种假设通常不会损害预测结果,但转换为浮点数会与双精度预测产生微小的差异。如果预测函数是连续的,即 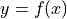 ,那么
,那么 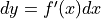 。我们可以确定差异的上界:
。我们可以确定差异的上界: 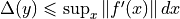 。*dx* 是浮点数转换引入的差异,
。*dx* 是浮点数转换引入的差异,dx = x - numpy.float32(x)。
然而,并非所有模型都是如此。为回归训练的决策树不是一个连续函数。因此,即使很小的 *dx* 也可能引入巨大的差异。我们来看一个总是会产生差异的示例,以及一些克服这种情况的方法。
深入了解问题¶
下面的示例是故意设计来失败的。它包含数量级不同且四舍五入到整数的整数特征。决策树将特征与阈值进行比较。在大多数情况下,浮点数和双精度数的比较会得到相同的结果。我们用 ![[x]_{f32}](../_images/math/3b4d86b00d6c15831b3feb5246c37584439fdbdc.png) 表示转换(或强制类型转换)
表示转换(或强制类型转换)numpy.float32(x)。
![x \leqslant y = [x]_{f32} \leqslant [y]_{f32}](../_images/math/c775a834bb5329566e258254aaedd2acbdc6a3b1.png)
然而,两次比较给出不同结果的概率并非为零。下面的图显示了不一致的区域。
from skl2onnx.sklapi import CastTransformer
from skl2onnx import to_onnx
from onnxruntime import InferenceSession
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.datasets import make_regression
import numpy
import matplotlib.pyplot as plt
def area_mismatch_rule(N, delta, factor, rule=None):
if rule is None:
def rule(t):
return numpy.float32(t)
xst = []
yst = []
xsf = []
ysf = []
for x in range(-N, N):
for y in range(-N, N):
dx = (1.0 + x * delta) * factor
dy = (1.0 + y * delta) * factor
c1 = 1 if numpy.float64(dx) <= numpy.float64(dy) else 0
c2 = 1 if numpy.float32(dx) <= rule(dy) else 0
key = abs(c1 - c2)
if key == 1:
xsf.append(dx)
ysf.append(dy)
else:
xst.append(dx)
yst.append(dy)
return xst, yst, xsf, ysf
delta = 36e-10
factor = 1
xst, yst, xsf, ysf = area_mismatch_rule(100, delta, factor)
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
ax.plot(xst, yst, ".", label="agree")
ax.plot(xsf, ysf, ".", label="disagree")
ax.set_title("Region where x <= y and (float)x <= (float)y agree")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.plot([min(xst), max(xst)], [min(yst), max(yst)], "k--")
ax.legend()
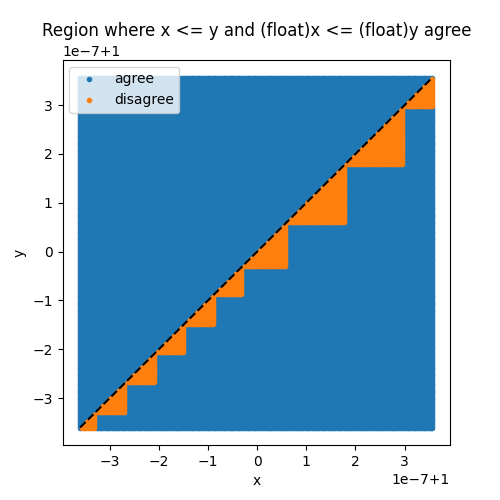
<matplotlib.legend.Legend object at 0x7414d868c470>
管道和数据¶
现在我们可以构建一个示例,其中学习到的决策树在此不一致区域中进行许多比较。这是通过将特征四舍五入到整数来实现的,这在处理分类特征时是常见的情况。
X, y = make_regression(10000, 10)
X_train, X_test, y_train, y_test = train_test_split(X, y)
Xi_train, yi_train = X_train.copy(), y_train.copy()
Xi_test, yi_test = X_test.copy(), y_test.copy()
for i in range(X.shape[1]):
Xi_train[:, i] = (Xi_train[:, i] * 2**i).astype(numpy.int64)
Xi_test[:, i] = (Xi_test[:, i] * 2**i).astype(numpy.int64)
max_depth = 10
model = Pipeline(
[("scaler", StandardScaler()), ("dt", DecisionTreeRegressor(max_depth=max_depth))]
)
model.fit(Xi_train, yi_train)
差异¶
让我们重用第一个示例中实现的函数 比较 并查看转换。
def diff(p1, p2):
p1 = p1.ravel()
p2 = p2.ravel()
d = numpy.abs(p2 - p1)
return d.max(), (d / numpy.abs(p1)).max()
onx = to_onnx(model, Xi_train[:1].astype(numpy.float32), target_opset=15)
sess = InferenceSession(onx.SerializeToString(), providers=["CPUExecutionProvider"])
X32 = Xi_test.astype(numpy.float32)
skl = model.predict(X32)
ort = sess.run(None, {"X": X32})[0]
print(diff(skl, ort))
(np.float64(382.4155510420527), np.float64(3.761671828472914))
差异很显著。ONNX 模型在每一步都保留浮点数。
在 scikit-learn 中
CastTransformer¶
我们可以尝试到处使用双精度。不幸的是,ONNX ML Operators 只允许 *TreeEnsembleRegressor* 运算符使用浮点系数。我们可以在 scikit-learn 管道中将归一化器的输出强制转换为浮点数,以寻求折衷。
model2 = Pipeline(
[
("scaler", StandardScaler()),
("cast", CastTransformer()),
("dt", DecisionTreeRegressor(max_depth=max_depth)),
]
)
model2.fit(Xi_train, yi_train)
差异。
onx2 = to_onnx(model2, Xi_train[:1].astype(numpy.float32), target_opset=15)
sess2 = InferenceSession(onx2.SerializeToString(), providers=["CPUExecutionProvider"])
skl2 = model2.predict(X32)
ort2 = sess2.run(None, {"X": X32})[0]
print(diff(skl2, ort2))
(np.float64(382.4155510420527), np.float64(3.761671828472913))
这仍然会失败,因为 scikit-learn 中的归一化器和 ONNX 中的归一化器使用不同的类型。强制类型转换仍然发生,*dx* 仍然存在。要消除它,我们需要在 ONNX 归一化器中使用双精度。
model3 = Pipeline(
[
("cast64", CastTransformer(dtype=numpy.float64)),
("scaler", StandardScaler()),
("cast", CastTransformer()),
("dt", DecisionTreeRegressor(max_depth=max_depth)),
]
)
model3.fit(Xi_train, yi_train)
onx3 = to_onnx(
model3,
Xi_train[:1].astype(numpy.float32),
options={StandardScaler: {"div": "div_cast"}},
target_opset=15,
)
sess3 = InferenceSession(onx3.SerializeToString(), providers=["CPUExecutionProvider"])
skl3 = model3.predict(X32)
ort3 = sess3.run(None, {"X": X32})[0]
print(diff(skl3, ort3))
(np.float64(2.9351773491725908e-05), np.float64(5.7363589878633306e-08))
这行得通。这也意味着,当管道包含不连续函数时,更改计算类型是困难的。在使用决策树之前,最好在整个过程中保持相同的类型。
脚本总运行时间: (0 分 0.895 秒)