注意
转到末尾 下载完整的示例代码。
使用 LightGBM 回归器转换管道¶
在使用浮点数和 TreeEnsemble 运算符时观察到的差异(请参阅 切换到浮点数时出现问题)解释了为什么 LGBMRegressor 的转换器即使在使用浮点张量时也可能引入显著的差异。
库 lightgbm 是用双精度实现的。具有多个树的随机森林回归器通过将每棵树的预测相加来计算其预测。转换为 ONNX 后,此求和变为 ![\left[\sum\right]_{i=1}^F float(T_i(x))](../_images/math/a2d1c2f56276e05e34f6d2fc904dc71680fc1914.png) ,其中 F 是森林中的树数,
,其中 F 是森林中的树数,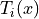 是第 i 棵树的输出,
是第 i 棵树的输出,![\left[\sum\right]](../_images/math/c4db1c515ae99a7a1062382cd305c1692428c162.png) 是浮点加法。差异可以表示为
是浮点加法。差异可以表示为 ![D(x) = |\left[\sum\right]_{i=1}^F float(T_i(x)) - \sum_{i=1}^F T_i(x)|](../_images/math/51210b969861f7df2fe22a76b7d03477a0aa7ce6.png) 。这随着森林中树的数量而增加。
。这随着森林中树的数量而增加。
为了减少影响,添加了一个选项,将 TreeEnsembleRegressor 节点拆分为多个节点,并这次使用双精度进行求和。如果我们假设该节点被拆分为 a 个节点,那么差异变为 ![D'(x) = |\sum_{k=1}^a \left[\sum\right]_{i=1}^{F/a} float(T_{ak + i}(x)) - \sum_{i=1}^F T_i(x)|](../_images/math/070692ac1405bf91a81a00816ad6fcaf5be87264.png) 。
。
训练 LGBMRegressor¶
import packaging.version as pv
import warnings
import timeit
import numpy
from pandas import DataFrame
import matplotlib.pyplot as plt
from tqdm import tqdm
from lightgbm import LGBMRegressor
from onnxruntime import InferenceSession
from skl2onnx import to_onnx, update_registered_converter
from skl2onnx.common.shape_calculator import (
calculate_linear_regressor_output_shapes,
)
from onnxmltools import __version__ as oml_version
from onnxmltools.convert.lightgbm.operator_converters.LightGbm import (
convert_lightgbm,
)
N = 1000
X = numpy.random.randn(N, 20)
y = numpy.random.randn(N) + numpy.random.randn(N) * 100 * numpy.random.randint(
0, 1, 1000
)
reg = LGBMRegressor(n_estimators=1000)
reg.fit(X, y)
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000352 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 5100
[LightGBM] [Info] Number of data points in the train set: 1000, number of used features: 20
[LightGBM] [Info] Start training from score 0.047562
注册 LGBMClassifier 的转换器¶
转换器实现在 onnxmltools 中:onnxmltools…LightGbm.py。以及形状计算器:onnxmltools…Regressor.py。
def skl2onnx_convert_lightgbm(scope, operator, container):
options = scope.get_options(operator.raw_operator)
if "split" in options:
if pv.Version(oml_version) < pv.Version("1.9.2"):
warnings.warn(
"Option split was released in version 1.9.2 but %s is "
"installed. It will be ignored." % oml_version,
stacklevel=0,
)
operator.split = options["split"]
else:
operator.split = None
convert_lightgbm(scope, operator, container)
update_registered_converter(
LGBMRegressor,
"LightGbmLGBMRegressor",
calculate_linear_regressor_output_shapes,
skl2onnx_convert_lightgbm,
options={"split": None},
)
转换¶
我们按照两种场景转换相同的模型,一种是单个 TreeEnsembleRegressor 节点,或者更多。split 参数是每个 TreeEnsembleRegressor 节点的树数。
model_onnx = to_onnx(
reg, X[:1].astype(numpy.float32), target_opset={"": 14, "ai.onnx.ml": 2}
)
model_onnx_split = to_onnx(
reg,
X[:1].astype(numpy.float32),
target_opset={"": 14, "ai.onnx.ml": 2},
options={"split": 100},
)
差异¶
sess = InferenceSession(
model_onnx.SerializeToString(), providers=["CPUExecutionProvider"]
)
sess_split = InferenceSession(
model_onnx_split.SerializeToString(), providers=["CPUExecutionProvider"]
)
X32 = X.astype(numpy.float32)
expected = reg.predict(X32)
got = sess.run(None, {"X": X32})[0].ravel()
got_split = sess_split.run(None, {"X": X32})[0].ravel()
disp = numpy.abs(got - expected).sum()
disp_split = numpy.abs(got_split - expected).sum()
print("sum of discrepancies 1 node", disp)
print("sum of discrepancies split node", disp_split, "ratio:", disp / disp_split)
/home/xadupre/vv/this312/lib/python3.12/site-packages/sklearn/utils/validation.py:2735: UserWarning: X does not have valid feature names, but LGBMRegressor was fitted with feature names
warnings.warn(
sum of discrepancies 1 node 0.00012160677476348304
sum of discrepancies split node 4.63712861652565e-05 ratio: 2.6224585259529944
差异总和减少了 4、5 倍。最大值也好多了。
disc = numpy.abs(got - expected).max()
disc_split = numpy.abs(got_split - expected).max()
print("max discrepancies 1 node", disc)
print("max discrepancies split node", disc_split, "ratio:", disc / disc_split)
max discrepancies 1 node 1.223684760631727e-06
max discrepancies split node 4.101712844928329e-07 ratio: 2.9833506315411236
处理时间¶
处理时间变慢了,但不是很多。
print(
"processing time no split",
timeit.timeit(lambda: sess.run(None, {"X": X32})[0], number=150),
)
print(
"processing time split",
timeit.timeit(lambda: sess_split.run(None, {"X": X32})[0], number=150),
)
processing time no split 1.527292794999994
processing time split 1.880056143000047
拆分影响¶
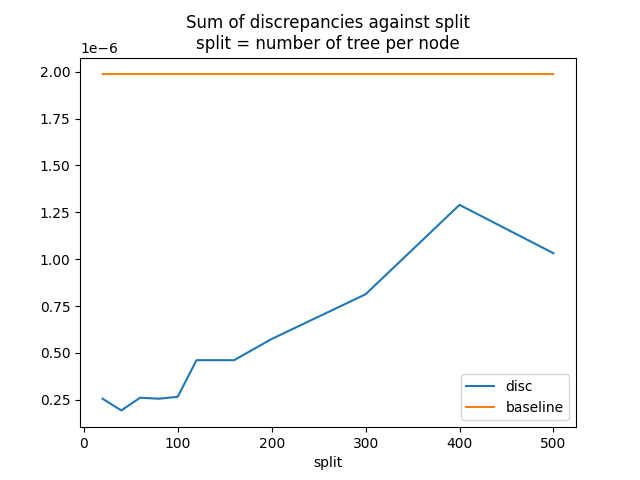
让我们看看差异总和如何随着参数 split 的变化而移动。
res = []
for i in tqdm([*range(20, 170, 20), 200, 300, 400, 500]):
model_onnx_split = to_onnx(
reg,
X[:1].astype(numpy.float32),
target_opset={"": 14, "ai.onnx.ml": 2},
options={"split": i},
)
sess_split = InferenceSession(
model_onnx_split.SerializeToString(), providers=["CPUExecutionProvider"]
)
got_split = sess_split.run(None, {"X": X32})[0].ravel()
disc_split = numpy.abs(got_split - expected).max()
res.append(dict(split=i, disc=disc_split))
df = DataFrame(res).set_index("split")
df["baseline"] = disc
print(df)
0%| | 0/12 [00:00<?, ?it/s]
8%|▊ | 1/12 [00:01<00:19, 1.77s/it]
17%|█▋ | 2/12 [00:03<00:15, 1.59s/it]
25%|██▌ | 3/12 [00:04<00:14, 1.59s/it]
33%|███▎ | 4/12 [00:06<00:11, 1.48s/it]
42%|████▏ | 5/12 [00:07<00:09, 1.42s/it]
50%|█████ | 6/12 [00:08<00:08, 1.45s/it]
58%|█████▊ | 7/12 [00:10<00:07, 1.41s/it]
67%|██████▋ | 8/12 [00:11<00:05, 1.44s/it]
75%|███████▌ | 9/12 [00:13<00:04, 1.39s/it]
83%|████████▎ | 10/12 [00:14<00:02, 1.36s/it]
92%|█████████▏| 11/12 [00:15<00:01, 1.39s/it]
100%|██████████| 12/12 [00:17<00:00, 1.37s/it]
100%|██████████| 12/12 [00:17<00:00, 1.43s/it]
disc baseline
split
20 2.992593e-07 0.000001
40 2.075150e-07 0.000001
60 2.874813e-07 0.000001
80 2.700104e-07 0.000001
100 4.101713e-07 0.000001
120 3.104678e-07 0.000001
140 3.350883e-07 0.000001
160 4.532249e-07 0.000001
200 3.900536e-07 0.000001
300 7.141194e-07 0.000001
400 6.281997e-07 0.000001
500 6.714246e-07 0.000001
图。
脚本总运行时间: (0 分 24.201 秒)