注意
转到末尾 下载完整的示例代码。
基准测试 ONNX 转换¶
示例 训练和部署 scikit-learn 管道 转换了一个简单的模型。本示例采用了一个基于随机数据的类似示例,并比较了每种选项计算预测所需的时间。
训练管道¶
import numpy
from pandas import DataFrame
from tqdm import tqdm
from onnx.reference import ReferenceEvaluator
from sklearn import config_context
from sklearn.datasets import make_regression
from sklearn.ensemble import (
GradientBoostingRegressor,
RandomForestRegressor,
VotingRegressor,
)
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from onnxruntime import InferenceSession
from skl2onnx import to_onnx
from skl2onnx.tutorial import measure_time
N = 11000
X, y = make_regression(N, n_features=10)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.01)
print("Train shape", X_train.shape)
print("Test shape", X_test.shape)
reg1 = GradientBoostingRegressor(random_state=1)
reg2 = RandomForestRegressor(random_state=1)
reg3 = LinearRegression()
ereg = VotingRegressor([("gb", reg1), ("rf", reg2), ("lr", reg3)])
ereg.fit(X_train, y_train)
Train shape (110, 10)
Test shape (10890, 10)
测量处理时间¶
我们使用函数 skl2onnx.tutorial.measure_time()。assume_finite 页可能会在您需要优化预测时有所帮助。我们测量每条观测值的处理时间,无论该观测值属于批次还是单个值。
sizes = [(1, 50), (10, 50), (100, 10)]
with config_context(assume_finite=True):
obs = []
for batch_size, repeat in tqdm(sizes):
context = {"ereg": ereg, "X": X_test[:batch_size]}
mt = measure_time(
"ereg.predict(X)", context, div_by_number=True, number=10, repeat=repeat
)
mt["size"] = context["X"].shape[0]
mt["mean_obs"] = mt["average"] / mt["size"]
obs.append(mt)
df_skl = DataFrame(obs)
df_skl
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:03<00:06, 3.43s/it]
67%|██████▋ | 2/3 [00:06<00:03, 3.36s/it]
100%|██████████| 3/3 [00:07<00:00, 2.19s/it]
100%|██████████| 3/3 [00:07<00:00, 2.51s/it]
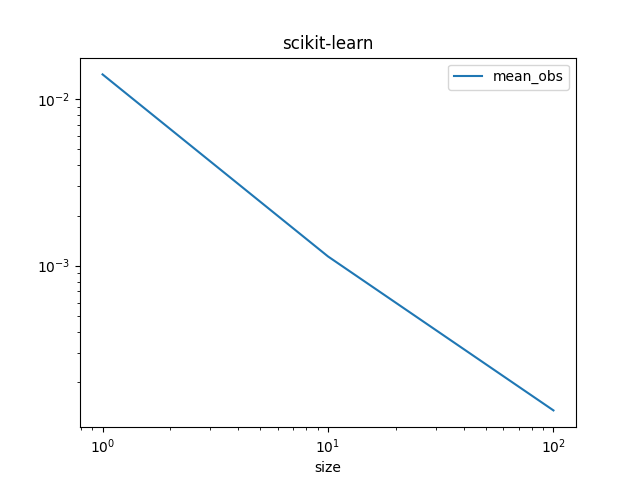
图。
df_skl.set_index("size")[["mean_obs"]].plot(title="scikit-learn", logx=True, logy=True)
ONNX Runtime¶
同样的操作也对两个可用的 ONNX Runtime 进行。
onx = to_onnx(ereg, X_train[:1].astype(numpy.float32), target_opset=14)
sess = InferenceSession(onx.SerializeToString(), providers=["CPUExecutionProvider"])
oinf = ReferenceEvaluator(onx)
obs = []
for batch_size, repeat in tqdm(sizes):
# scikit-learn
context = {"ereg": ereg, "X": X_test[:batch_size].astype(numpy.float32)}
mt = measure_time(
"ereg.predict(X)", context, div_by_number=True, number=10, repeat=repeat
)
mt["size"] = context["X"].shape[0]
mt["skl"] = mt["average"] / mt["size"]
# onnxruntime
context = {"sess": sess, "X": X_test[:batch_size].astype(numpy.float32)}
mt2 = measure_time(
"sess.run(None, {'X': X})[0]",
context,
div_by_number=True,
number=10,
repeat=repeat,
)
mt["ort"] = mt2["average"] / mt["size"]
# ReferenceEvaluator
context = {"oinf": oinf, "X": X_test[:batch_size].astype(numpy.float32)}
mt2 = measure_time(
"oinf.run(None, {'X': X})[0]",
context,
div_by_number=True,
number=10,
repeat=repeat,
)
mt["pyrt"] = mt2["average"] / mt["size"]
# end
obs.append(mt)
df = DataFrame(obs)
df
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:08<00:16, 8.39s/it]
67%|██████▋ | 2/3 [00:23<00:12, 12.20s/it]
100%|██████████| 3/3 [00:39<00:00, 13.94s/it]
100%|██████████| 3/3 [00:39<00:00, 13.09s/it]
图。
df.set_index("size")[["skl", "ort", "pyrt"]].plot(
title="Average prediction time per runtime", logx=True, logy=True
)
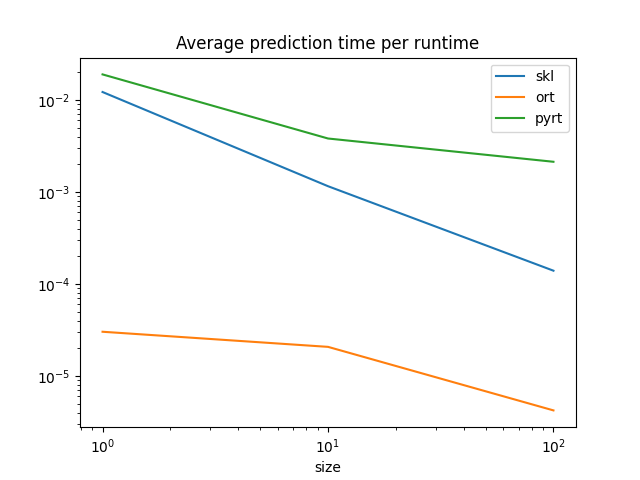
ONNX Runtime 比 scikit-learn 预测单个观测值快得多。scikit-learn 针对训练和批量预测进行了优化。这解释了为什么 scikit-learn 和 ONNX Runtime 在大批量预测时看起来会收敛。它们使用了类似的实现、并行化和语言(C++,openmp)。
脚本总运行时间: (0 分 47.729 秒)