注意
转到末尾 下载完整的示例代码。
使用其他转换器实现新转换器¶
在许多情况下,自定义模型会利用已有关联转换器的现有模型。要转换这种拼凑的模型,必须调用现有的转换器。本示例将演示如何执行此操作。示例 实现新转换器 可以通过使用 PCA 来重写。然后,我们可以重新使用与此模型关联的转换器。
自定义模型¶
让我们使用 scikit-learn API 实现一个简单的自定义模型。该模型是预处理,可对相关随机变量进行去相关。如果 X 是特征矩阵,则 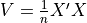 是协方差矩阵。我们计算
是协方差矩阵。我们计算 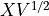 。
。
import pickle
from io import BytesIO
import numpy
from numpy.testing import assert_almost_equal
from onnxruntime import InferenceSession
from sklearn.base import TransformerMixin, BaseEstimator
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from skl2onnx import update_registered_converter
from skl2onnx.algebra.onnx_operator import OnnxSubEstimator
from skl2onnx import to_onnx
class DecorrelateTransformer(TransformerMixin, BaseEstimator):
"""
Decorrelates correlated gaussian features.
:param alpha: avoids non inversible matrices
by adding *alpha* identity matrix
*Attributes*
* `self.mean_`: average
* `self.coef_`: square root of the coveriance matrix
"""
def __init__(self, alpha=0.0):
BaseEstimator.__init__(self)
TransformerMixin.__init__(self)
self.alpha = alpha
def fit(self, X, y=None, sample_weights=None):
self.pca_ = PCA(X.shape[1])
self.pca_.fit(X)
return self
def transform(self, X):
return self.pca_.transform(X)
def test_decorrelate_transformer():
data = load_iris()
X = data.data
dec = DecorrelateTransformer()
dec.fit(X)
pred = dec.transform(X)
cov = pred.T @ pred
for i in range(cov.shape[0]):
cov[i, i] = 1.0
assert_almost_equal(numpy.identity(4), cov)
st = BytesIO()
pickle.dump(dec, st)
dec2 = pickle.load(BytesIO(st.getvalue()))
assert_almost_equal(dec.transform(X), dec2.transform(X))
test_decorrelate_transformer()
data = load_iris()
X = data.data
dec = DecorrelateTransformer()
dec.fit(X)
pred = dec.transform(X[:5])
print(pred)
[[-2.68412563e+00 3.19397247e-01 -2.79148276e-02 2.26243707e-03]
[-2.71414169e+00 -1.77001225e-01 -2.10464272e-01 9.90265503e-02]
[-2.88899057e+00 -1.44949426e-01 1.79002563e-02 1.99683897e-02]
[-2.74534286e+00 -3.18298979e-01 3.15593736e-02 -7.55758166e-02]
[-2.72871654e+00 3.26754513e-01 9.00792406e-02 -6.12585926e-02]]
转换为 ONNX¶
让我们尝试转换它,看看会发生什么。
try:
to_onnx(dec, X.astype(numpy.float32))
except Exception as e:
print(e)
Unable to find a shape calculator for type '<class '__main__.DecorrelateTransformer'>'.
It usually means the pipeline being converted contains a
transformer or a predictor with no corresponding converter
implemented in sklearn-onnx. If the converted is implemented
in another library, you need to register
the converted so that it can be used by sklearn-onnx (function
update_registered_converter). If the model is not yet covered
by sklearn-onnx, you may raise an issue to
https://github.com/onnx/sklearn-onnx/issues
to get the converter implemented or even contribute to the
project. If the model is a custom model, a new converter must
be implemented. Examples can be found in the gallery.
此错误意味着 DecorrelateTransformer 没有关联的转换器。我们来创建一个。它需要实现以下两个函数:一个形状计算器和一个与下面签名相同的转换器。首先是形状计算器。我们检索输入类型,然后告知输出类型具有相同的类型、相同的行数和特定的列数。
def decorrelate_transformer_shape_calculator(operator):
op = operator.raw_operator
input_type = operator.inputs[0].type.__class__
input_dim = operator.inputs[0].type.shape[0]
output_type = input_type([input_dim, op.pca_.components_.shape[1]])
operator.outputs[0].type = output_type
转换器。我们需要注意的一点是目标 opset。此信息对于确保每个节点都遵循该 opset 的规范进行定义很重要。
def decorrelate_transformer_converter(scope, operator, container):
op = operator.raw_operator
opv = container.target_opset
out = operator.outputs
# We retrieve the unique input.
X = operator.inputs[0]
# We tell in ONNX language how to compute the unique output.
# op_version=opv tells which opset is requested
Y = OnnxSubEstimator(op.pca_, X, op_version=opv, output_names=out[:1])
Y.add_to(scope, container)
我们需要让 skl2onnx 了解新的转换器。
update_registered_converter(
DecorrelateTransformer,
"SklearnDecorrelateTransformer",
decorrelate_transformer_shape_calculator,
decorrelate_transformer_converter,
)
onx = to_onnx(dec, X.astype(numpy.float32))
sess = InferenceSession(onx.SerializeToString(), providers=["CPUExecutionProvider"])
exp = dec.transform(X.astype(numpy.float32))
got = sess.run(None, {"X": X.astype(numpy.float32)})[0]
def diff(p1, p2):
p1 = p1.ravel()
p2 = p2.ravel()
d = numpy.abs(p2 - p1)
return d.max(), (d / numpy.abs(p1)).max()
print(diff(exp, got))
(np.float64(3.5601259806838925e-07), np.float64(0.00031583501773748286))
让我们检查一下使用双精度也能正常工作。
onx = to_onnx(dec, X.astype(numpy.float64))
sess = InferenceSession(onx.SerializeToString(), providers=["CPUExecutionProvider"])
exp = dec.transform(X.astype(numpy.float64))
got = sess.run(None, {"X": X.astype(numpy.float64)})[0]
print(diff(exp, got))
(np.float64(1.942890293094024e-15), np.float64(2.5733660162141577e-13))
如预期的那样,使用双精度时差异更小。
脚本总运行时间: (0 分钟 0.052 秒)